SQLite gives us the ability to create a simple relational database model which can be perfect for quickly getting data projects off the ground. However for any long-standing project, infrastructure needs to scale with demand and the data itself. The tables in your model will grow overtime and so will your data management needs. Enter PostreSQL! Postgres is a relational database maangement system that offers many features.
In this projectI migrate an entire SQLite database into PostgreSQL and explore the use of Views, which is a common but powerful feature.
Database Migration
Load sqlite database into Python
file into python environment using sqlite3 library
#connect to sqlite db file
sqlite_conn = sqlite3.connect("../sqlite/database.sqlite")
sqlite_cur = sqlite_conn.cursor()
#query all table names
tables_df = pd.DataFrame(sqlite_cur.execute("SELECT name FROM sqlite_master WHERE type='table'"))
tables_df.columns = [i[0] for i in sqlite_cur.description
tables in SQLite database

Query all data into dataframes
from the loaded data model and convert into dataframes
#create dictionary with table names that will hold table data
df_dict = {'reviews':None,'artists':None,'genres':None,'labels':None,
'years':None,'content':None}
for i in list(df_dict.keys()): #iterate through dictionary
df_dict[i] = pd.DataFrame(sqlite_cur.execute(f'SELECT * FROM {i}')) #query each table and create dataframe object
df_dict[i].columns = [i[0] for i in sqlite_cur.description] #get header/columns
Reviewing Dataframes sample

Load dataframes into Postgres database as tables
use pandas “to_sql” attribute to crete tables and load data into database via the defined database connection .
#create sqlaclechemy database connection with newly created database
database = f"postgresql+psycopg2://{config.db_user}:{config.db_password}@localhost:5432/pitchfork?gssencmode=disable"
engine = create_engine(database)
for i in list(df_dict.keys()): #iterate through dictionary taht holds dataframes of data
df_dict[i].to_sql(name=i, index=False, con=engine, if_exists='replace', chunksize=100000) # load data into database
print(f"Table {i} loaded")
Database Design: Non-materialized Views
With the data now fully loaded, we can query it dirctly through the database managemnt system. As well as use tools native to the environment, succh as ERD Diagrams. Which allow an easy overhead view of the tables and its columns:
Database genrated ERD Diagram
With confirmation that our data has been loaded in the same format as it was held in the sqlite db file, we can now create some views.
Creating Views
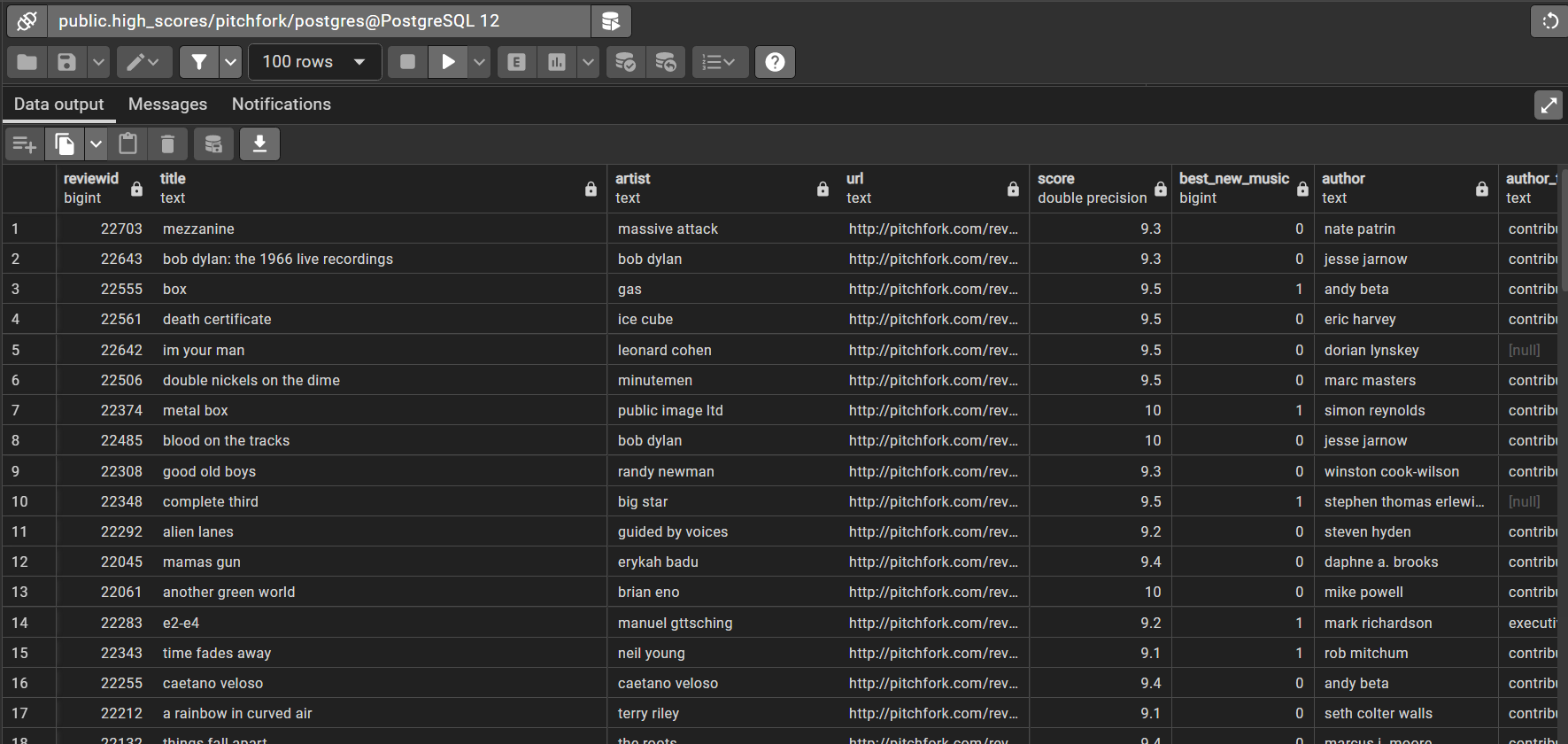
-- create a view for reviews with highscores
CREATE VIEW high_scores AS
SELECT * FROM reviews
WHERE reviews.score > 9
Querying "high_scores" View
--create view for top genres by review count
CREATE VIEW top_genres_by_reviews AS
SELECT genres.genre AS "Genre", COUNT(reviews.reviewid) AS "Review COUNT" FROM
genres
LEFT JOIN
reviews
ON genres.reviewid = reviews.reviewid
WHERE Genre IS NOT null
GROUP BY genres.genre
ORDER BY genres.genre DESC
Querying "top_genres_by_reviews" View

--create view for top 10 artists by review count for each year
CREATE OR REPLACE VIEW ranked_artists_y AS
with ranked_artists AS (
SELECT pub_year, artist, COUNT(reviewid) "Review COUNT",
ROW_NUMBER() OVER(
partition by pub_year
order by count(reviewid) DESC ) row_num
from reviews
group by pub_year, artist )
select pub_year, artist, "Review Count", row_num
from ranked_artists
where row_num between 1 and 10
Querying "ranked_artists_y" View

With views created its easy to gain insights and answer analytic questions as more data is added.